
Furhat blog
Making sense of Google Duplex — An assessment of Google’s latest innovation

Gabriel Skantze
Co-founder & Chief Scientist
Earlier this week, Google presented Duplex, an AI system that can have natural interactions over the phone to schedule hair salon appointments or make restaurant bookings. Reactions to new technology tends to polarize opinion, and Google Duplex has seemed to split opinion more than most. Rather than wade in on the ethical implications, which should by no means be ignored, I thought it would be interesting to put the technical achievements into perspective and discuss its implications for the AI / robotics industry.
First of all, it’s worth mentioning that the power of any idea lies in its execution. And the demonstrations we heard of Google Duplex were truly impressive, which was reflected by the reactions from the audience and the response afterwards in the media. The computer seemed to understand whatever the human said, and its responses were executed with almost perfect tone and timing, sounding human-like in a way we are not used to hearing. Of course, we do not know to what extent these examples reflect the average call, or whether they were chosen because they ended up sounding so natural. But assuming they are representative, what is it that Google has managed to achieve that makes them appear so natural?
Conversational systems typically consist of at least five components:
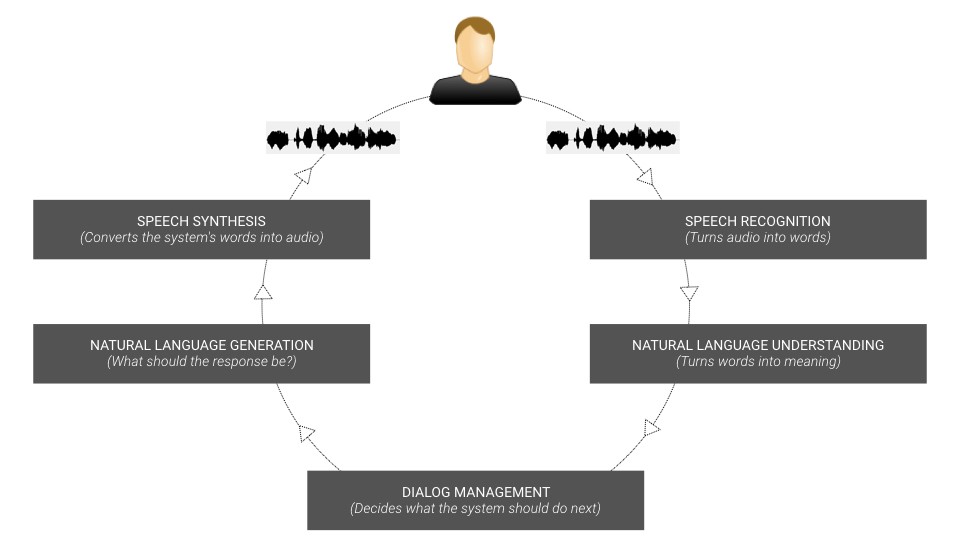
Normally, these components are “trained” separately, and the Speech Recognition and Speech Synthesis components are often trained on generic user behavior, so that they can be reused across different types of situations. However, this also means that the performance of each component is less than ideal, since people speak and react differently depending on the situation. One of the things Google has done in Duplex, according to their blog post, is to train all their components in a more holistic fashion, which allows them to improve the overall performance. However, this can only be done if you have access to thousands (if not millions) of restaurant bookings or hair appointments to train on.
An additional, very important, requirement is that the conversation is very specific. It would simply not be possible for Duplex to sound so convincing if the situation was something more general. Humans have the remarkable skill of learning a new task from just a few examples. No AI of today can do that.
Even though Google has been working on Duplex for many years, they have focussed on three, very specific examples which indicates how much work goes into fine-tuning each of them. Every new situation (booking a doctor’s appointment for example) will require a substantial amount of work to sound convincing and given the plethora of apps Google Assistant and Amazon Alexa provide, often built by third-party developers who do not have these resources, we are not likely to see this type of interaction in our voice assistants in the near future.
I also think there is another key reason why Duplex seems to work so well, that people might not think about, and that is the reversed roles of the computer and human. In more traditional settings, the human would be the one making the phone call to the computer to schedule a haircut. In my mind, this switch of roles is likely to make the task easier, rather than harder. The business person answering the call has a strong incentive to be as compliant as possible, and is not likely to switch topic, or to be uncertain about what they really want. They are used to taking these kinds of phone calls, and the structure and possible paths of the conversation is limited.
To get a better understanding of the scope of the situation, and what is actually going on, it can help to not just listen to them, but to look at them in more detail. When designing and developing dialog systems, it often helps to classify sentences by their intent (or “dialog act”), which is a label that describes the overall meaning of the sentence. This partly describes what the system must be able to do: to map the user’s words to an intent, and then decide what it needs to do next. Let’s look at the hair salon example (where the intent is shown in the rightmost column):
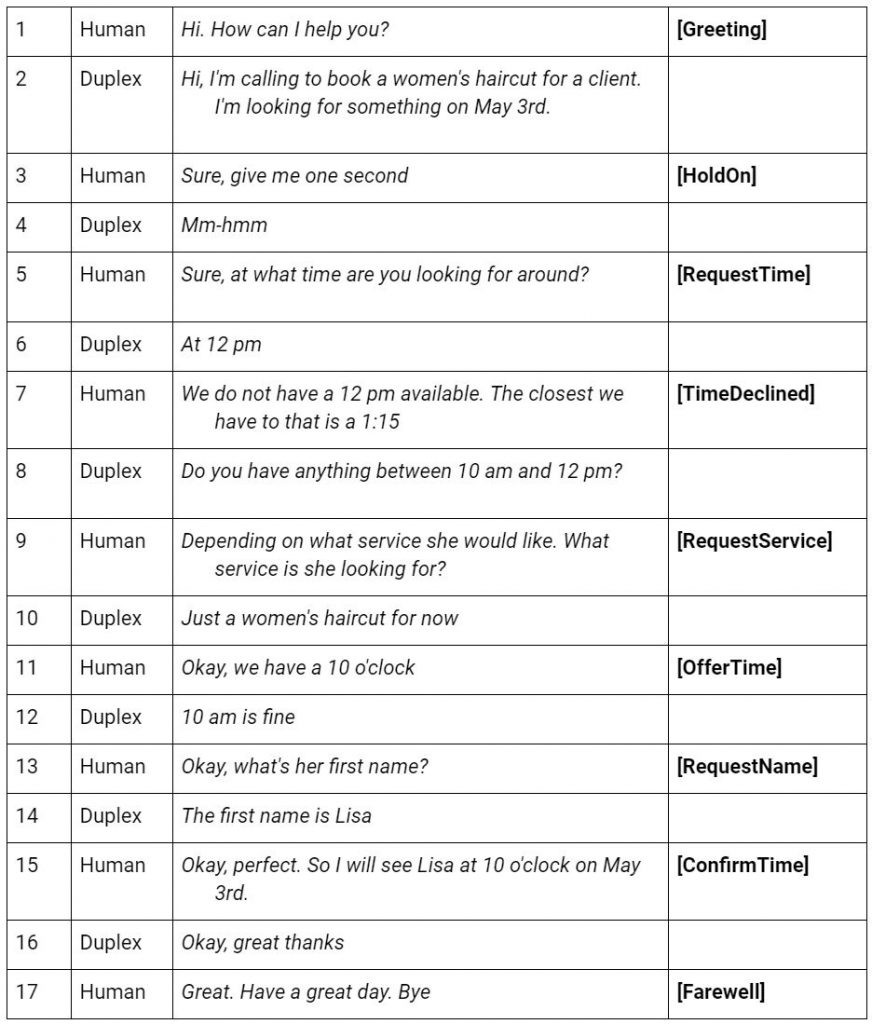
When we look at the interaction this way, the “AI” might not appear as futuristic, as when you first listen to it. The mapping between the words that the user says, and their corresponding intent, is fairly straightforward, especially given the amount of examples Google must have in this limited situation. For example, even if the semantics of turn 7 seems to be complex, the system only needs to understand that the suggested time does not work (TimeDeclined), and then give a more specific time interval. There are no complex topic shifts or ambiguous counter-questions, which could otherwise be challenging for a dialog system. This is not to say that the task is simple, just that it does not go beyond state-of-the-art in terms of conversational AI.
So, if the natural language understanding or dialogue management are not the truly impressive parts of this demo, what is it then? The speech recognition seems to do an impressive job, especially in the restaurant booking demonstration. But we are already getting used to seeing speech recognition getting better every day, and as we have discussed, Google can fine-tune their models on large amounts of data. Of course, we do not know the actual speech recognition performance in these examples, so it could also be the case that the holistic training of the system helps it to cope with errors and uncertainties.
To me, the most exciting aspect of Google Duplex is the fact that someone is finally addressing conversational speech synthesis and its application to spoken dialog systems. For a long time, speech synthesis was mainly intended to be used for reading texts and not to sound like it was part of a conversation. In conversation, people use so-called backchannels (“mhm”), they make hesitation sounds (“uhm…”), correct themselves, change the intonation depending on whether they pose a question or make a statement, and whether they sound certain or not. Also, the speaking rate varies much more than in read speech. Unfortunately, these features have so far been neglected by the speech synthesis providers. Many researchers in dialogue systems (including myself), have investigated for many years how dialogue systems should be able to generate more conversational speech and interact more fluently, but since we have been using off-the-shelf speech synthesis components, it has simply not been possible to generate demonstrations as convincing as Google Duplex. Thanks to Google’s recent advancements in speech synthesis, this will hopefully change.
What the Google Duplex demo really shows is the enormous effect the quality and naturalness of the speech synthesis has on people’s perception. If you would take the dialog above and replace the conversational speech synthesis with “standard” speech synthesis prompts, I doubt we would have been nearly as impressed. Hopefully, this will now spark a stronger push for the development of conversational speech synthesis. How this new synthesis should then be used in conversational systems, when we don’t have extremely limited domains and tons of data, is an open question.


